Links to This Note9
- Project Malmantile... subproject of Project Florence. Supercedes Project Fiesole
- Project Florence- Project Fiesole
- 2023-10-23- Project Fiesole
- 2023-10-17- Project Fiesole
- 2023-10-13- Project Fiesole
- 2023-10-12- Project Fiesole
- 2023-10-10- Project Fiesole
- 2023-10-04- Project Fiesole
- 2023-10-03- Project Fiesole
Project Fiesole
TL;DR:
Can we VFL MNIST?
Project Fiesole aims to demonstrate the feasibility of integrating CNN architectures within Vertical Federated Learning to enhance data-driven models without compromising data privacy. In this context, data exists in islands, meaning various entities or organizations possess distinct features for the same sample population. Rather than consolidating these diverse datasets, Vertical Federated Learning allows for collaborative model training where each entity contributes its unique feature set. This approach not only upholds data privacy but also leverages the richness of diverse input parameters, offering a holistic perspective that a singular dataset might miss. Fiesole is a subproject of Project Florence.
Method
In VFL, each island has different "input parameters" for the same "subject". Thus, we split the original image (here, 9) into four distinct pieces in this demo. Each of them will necessarily work as a "distinct input."

I created four training sets, one for each quadrant, with masking.
Control Group
Ran entire ten epochs with the original dataset
- MNIST CNN: 99.16 %
One by One
I ran ten epochs on one dataset and have yet to come back. Then I moved on to the next one.
- TL(10): 26.82 %
- TL(10), TR(10): 36.44 %
- TL(10), TR(10), BL(10): 30.66 %
- TL(10), TR(10), BL(10), BR(10): 47.24 %
Round Robin
Round-robin
I ran one epoch on TL and moved on to TR, BL, and BR. Then came back. Ran four cycles, thus 16 epochs.
- Cycle 1
- TL(1): 59.37 %
- TL(1), TR(1): 79.6 %
- TL(1), TR(1), BL(1): 88.51 %
- TL(1), TR(1), BL(1), BR(1): 79.88 %
- Cycle 2
- TL(1): 85.68 %
- TL(1), TR(1): 87.69 %
- TL(1), TR(1), BL(1): 91.4 %
- TL(1), TR(1), BL(1), BR(1): 88.52 %
- Cycle 3
- TL(1): 82.21 %
- TL(1), TR(1): 86.56 %
- TL(1), TR(1), BL(1): 90.98 %
- TL(1), TR(1), BL(1), BR(1): 89.07 %
- Cycle 4
- TL(1): 85.24 %
- TL(1), TR(1): 86.33 %
- TL(1), TR(1), BL(1): 91.99 %
- TL(1), TR(1), BL(1), BR(1): 90.12 %
Round Robin, 10 cycles
Still around 92%, max. Never goes above 95%.
Federated Learning
Results
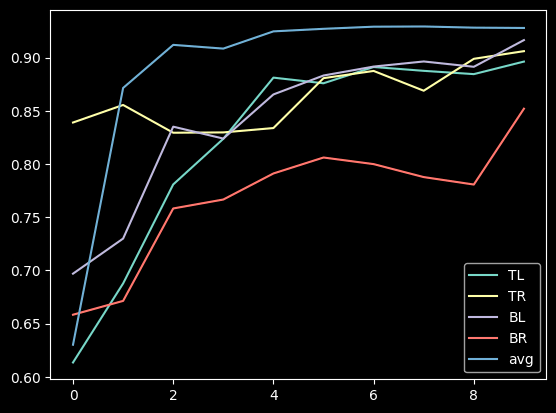
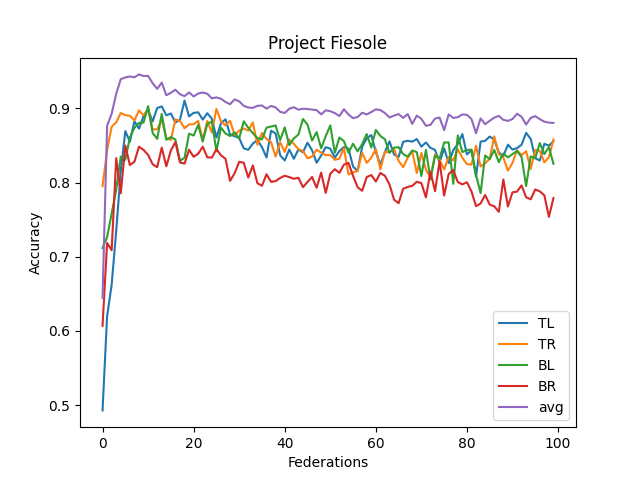
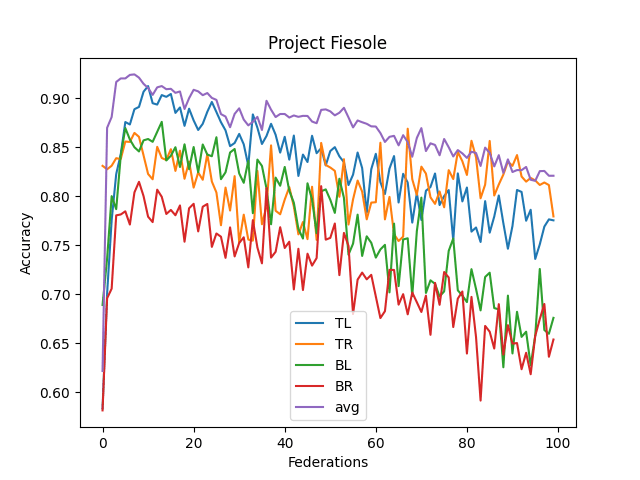
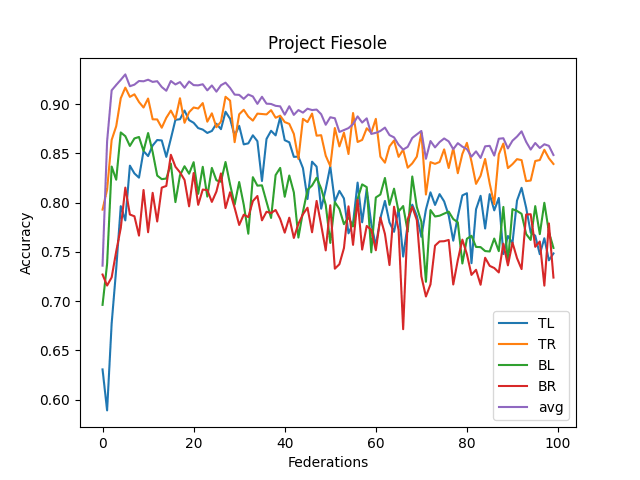
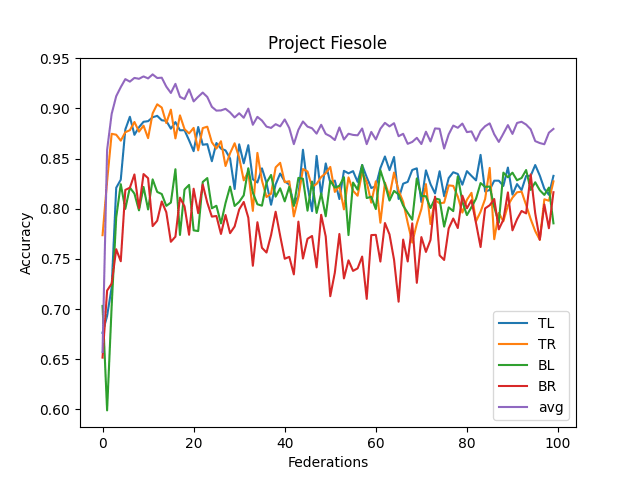
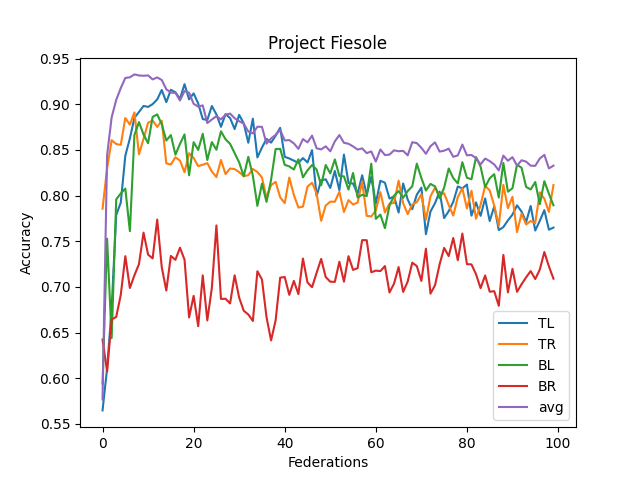
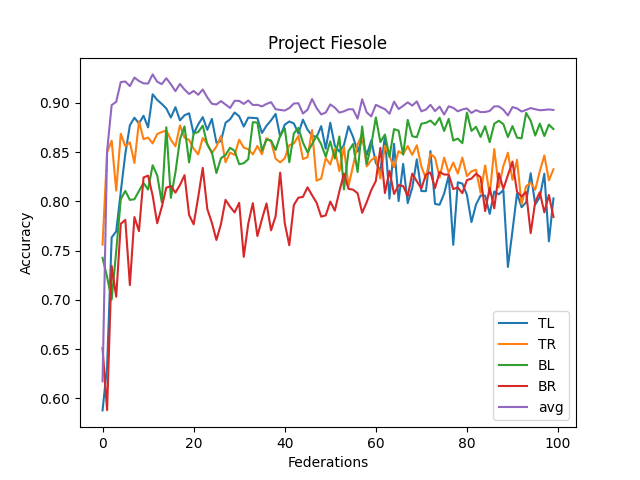
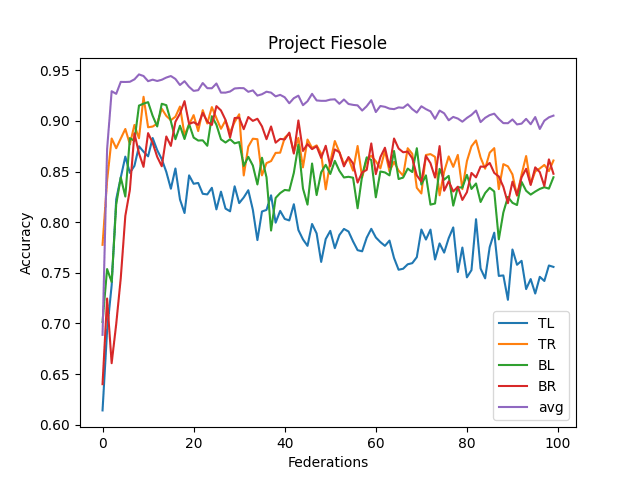
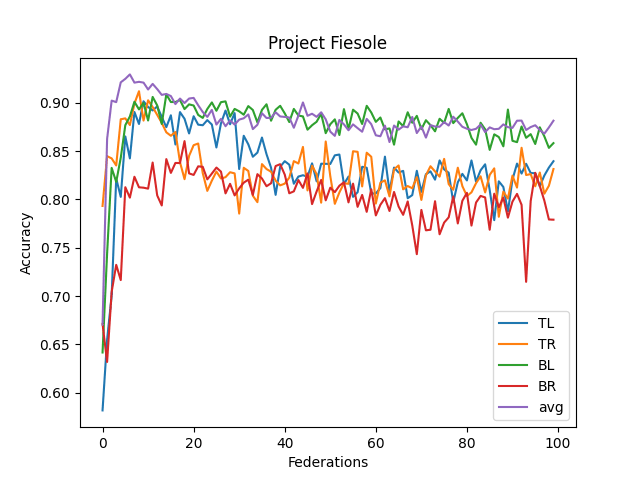
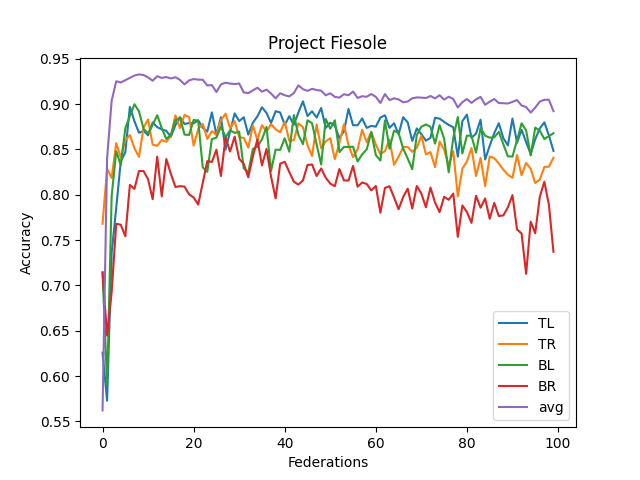
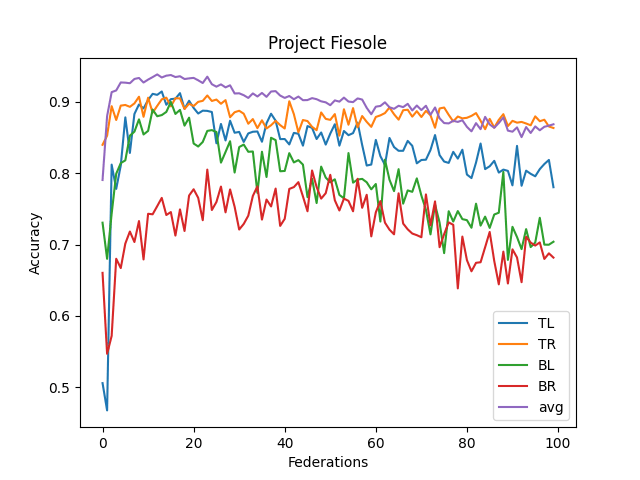
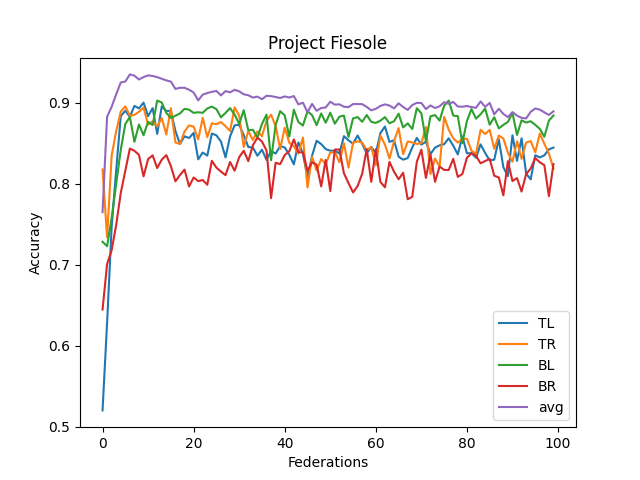
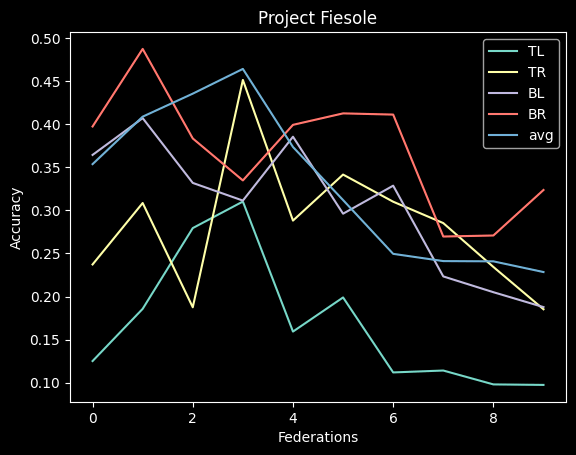
- The averaged model maxes its accuracy around 10-15 federations. Before each federation, each learner trains ten epochs from their corresponding dataset.
- It never reaches over 95% accuracy.
- This contrasts with the full CNN, where it quickly reaches 98% accuracy
- I think this comes from the lack of understanding "across quadrants."
- I didn't implement optimizing features (dropout, reducing LR, etc.)
Adjustments
- Instead of just blacking out the three quadrants (i.e., only leaving one quadrant), I'll try to add some noise (i.e., a random number from 0-255) to the blacked-out three quadrants to see any differences. I hypothesize that this can mimic or simulate knowledge across quadrants, slightly improving performance.
- 4

- 5

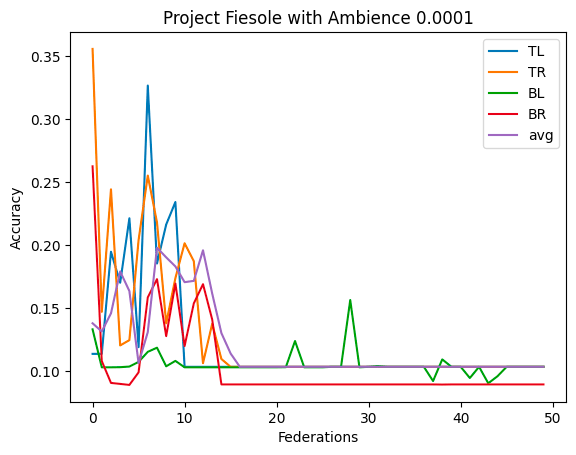
- Update: Adding ambient noise decreases the accuracy a lot, both when I use the same ambient pattern (throughout the federations, uses the same ambient pattern over and over) or dynamically generate them (throughout the federations, create a new ambient pattern)
Next Steps
- I'll start working on implementing CIFAR-10 with a similar architecture.
Summary
- Performance Benchmark: The current VFL model peaks at around 93% accuracy within 10-15 epochs. In contrast, a complete CNN trained on the entire dataset can quickly achieve an accuracy of 98%.
- Recognition Across Quadrants: the neural network's capability to recognize consistent patterns across different data segments (or quadrants) is a significant concern.
- The Record Linkage Challenge: The current architecture does not factor in "Record Linkage" -- a mechanism to understand consistent data criteria across different quadrants. Incorporating this might be the key to breaching the 95%+ accuracy barrier.
Potential Solutions
- Unique Image Identifiers: A proposal includes assigning unique numeric IDs to images and their respective quadrants. The hypothesis is that this would help the neural network learn patterns and relationships between various quadrants.
- Training Variations: Different training methods using these IDs have been proposed, ranging from single-example training to batching. However, there are concerns about efficiency and computational speed.
- Introducing Noise: I proposed the addition of random noise to the blacked-out sections of the image. This might simulate knowledge across the quadrants and improve the model's accuracy.
Other Considerations
- Testing Methodology: It has been clarified that a separate test set for evaluation exists. All quadrant and average learners utilize this set purely for evaluation.
- Code Review: A specific code section has been shared on GitHub for a deeper technical understanding, indicating open collaboration and further fine-tuning.
Feedback and Recommendations
- Noise Introduction: Caution is advised on the noise addition mechanism. Instead of a broad range, a much smaller noise range has been recommended to prevent the network from overfitting.
- Further Discussions: Given the complexities and potential solutions, in-person discussions or more detailed meetings have been deemed necessary to refine the approach.
Status
✅ SUCCESS
Further Actions
Superseded by anaclumos/malmantile Project Malmantile